系列文章目录
前言
本综合指南提供了在英伟达 Jetson设备上部署Ultralytics YOLOv8 的详细攻略。此外,它还展示了性能基准,以证明YOLOv8 在这些小巧而功能强大的设备上的性能。

备注
本指南使用Seeed Studio reComputer J4012进行测试,它基于运行最新稳定JetPack版本JP5.1.3的NVIDIA Jetson Orin NX 16GB。对于较旧的 Jetson 设备,如 Jetson Nano(仅支持 JP4.6.4 之前的版本),可能无法保证使用本指南。不过,本指南有望在所有运行 JP5.1.3 的 Jetson Orin、Xavier NX 和 AGX Xavier 设备上运行。
一、什么是 NVIDIA Jetson?
英伟达™(NVIDIA®)Jetson 是一系列嵌入式计算板卡,旨在为边缘设备带来加速的 AI(人工智能)计算。这些小巧而功能强大的设备围绕英伟达™(NVIDIA®)的GPU架构打造,能够直接在设备上运行复杂的人工智能算法和深度学习模型,而无需依赖云计算资源。Jetson 板卡通常用于机器人、自动驾驶汽车、工业自动化和其他需要在本地以低延迟和高效率执行人工智能推理的应用中。此外,这些板卡基于 ARM64 架构,与传统 GPU 计算设备相比运行功耗更低。
二、英伟达 Jetson 系列对比
Jetson Orin是英伟达 Jetson 系列的最新迭代产品,基于英伟达安培架构,与前几代产品相比,人工智能性能大幅提升。下表比较了生态系统中的几款 Jetson 设备。
| Jetson AGX Orin 64GB | Jetson Orin NX 16GB | Jetson Orin Nano 8GB | Jetson AGX Xavier | Jetson Xavier NX | Jetson Nano | |
|---|---|---|---|---|---|---|
| 人工智能性能 | 275 TOPS | 100 TOPS | 40 TOPs | 32 TOPS | 21 TOPS | 472 GFLOPS |
| GPU | 2048 核英伟达安培架构 GPU,64 个Tensor 内核 | 1024 核英伟达安培架构图形处理器,配备 32 个Tensor 内核 | 1024 核英伟达安培架构图形处理器,配备 32 个Tensor 内核 | 512 核英伟达 Volta 架构 GPU,64 个Tensor 内核 | 384 核英伟达 Volta™ 架构 GPU,配备 48 个Tensor 内核 | 128 核英伟达™(NVIDIA®)Maxwell™ 架构图形处理器 |
| 图形处理器最高频率 | 1.3 千兆赫 | 918 兆赫 | 625 兆赫 | 1377 兆赫 | 1100 兆赫 | 921MHz |
| 中央处理器 | 12 核 NVIDIA Arm® Cortex A78AE v8.2 64 位 CPU 3MB L2 + 6MB L3 | 8 核 NVIDIA Arm® Cortex A78AE v8.2 64 位 CPU 2MB L2 + 4MB L3 | 6 核 Arm® Cortex®-A78AE v8.2 64 位 CPU 1.5MB L2 + 4MB L3 | 8 核 NVIDIA Carmel Arm®v8.2 64 位 CPU 8MB L2 + 4MB L3 | 6 核 NVIDIA Carmel Arm®v8.2 64 位 CPU 6MB L2 + 4MB L3 | 四核 Arm® Cortex®-A57 MPCore 处理器 |
| CPU 最高频率 | 2.2 千兆赫 | 2.0 千兆赫 | 1.5 千兆赫 | 2.2 千兆赫 | 1.9 千兆赫 | 1.43GHz |
| 内存 | 64GB 256 位 LPDDR5 204.8GB/s | 16GB 128 位 LPDDR5 102.4GB/s | 8GB 128 位 LPDDR5 68 GB/s | 32GB 256 位 LPDDR4x 136.5GB/s | 8GB 128 位 LPDDR4x 59.7GB/s | 4GB 64 位 LPDDR4 25.6GB/s" |
如需更详细的比较表,请访问NVIDIA Jetson 官方网页的技术规格部分。
三、什么是 NVIDIA JetPack?
英伟达™(NVIDIA®)JetPack SDK为Jetson模块提供动力,是最全面的解决方案,为构建端到端加速人工智能应用提供了完整的开发环境,缩短了产品上市时间。JetPack 包括带有引导加载器的 Jetson Linux、Linux 内核、Ubuntu 桌面环境以及一整套用于加速 GPU 计算、多媒体、图形和计算机视觉的库。它还包括用于主机和开发者工具包的示例、文档和开发者工具,并支持更高级别的 SDK,如用于流媒体视频分析的 DeepStream、用于机器人技术的 Isaac 和用于对话式人工智能的 Riva。
四、将 Flash JetPack 插入英伟达™ Jetson
拿到 NVIDIA Jetson 设备后,第一步就是将 NVIDIA JetPack 闪存到设备上。闪存英伟达™ Jetson 设备有几种不同的方法。
- 如果你拥有官方的英伟达开发套件(如 Jetson Orin Nano 开发套件),可以访问此链接下载映像,并准备一张装有 JetPack 的 SD 卡以启动设备。
- 如果您拥有其他英伟达™(NVIDIA®)开发套件,可以访问此链接,使用SDK 管理器将 JetPack 闪存到设备。
- 如果你拥有 Seeed Studio reComputer J4012 设备,可以访问此链接将 JetPack 闪存到附带的固态硬盘中。
- 如果您拥有任何其他由英伟达™(NVIDIA®)Jetson 模块驱动的第三方设备,建议访问此链接进行命令行闪存。
备注
对于上述方法 3 和 4,在刷新系统并启动设备后,请在设备终端输入 "sudo apt update && sudo apt install nvidia-jetpack-y",以安装所需的所有剩余 JetPack 组件。
五、从 Docker 开始
在英伟达™(NVIDIA®)Jetson 上开始使用Ultralytics YOLOv8 的最快方法是使用为 Jetson 预制的 docker 镜像。
执行以下命令,提取 Docker 容器并在 Jetson 上运行。这是基于l4t-pytorchdocker 镜像,其中包含 Python3 环境中的PyTorch 和 Torchvision。
t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
六、不使用 Docker 启动
6.1 安装Ultralytics 软件包
在这里,我们将在 Jetson 上安装 ultralyics 软件包和可选依赖项,以便将PyTorch 模型导出为其他不同格式。我们将主要关注英伟达TensorRT 导出,因为 TensoRT 将确保我们能从 Jetson 设备中获得最高性能。
- 更新软件包列表,安装 pip 并升级到最新版本
sudo apt update sudo apt install python3-pip -y pip install -U pip - 安装
ultralyticspip 软件包与可选依赖项pip install ultralytics[export] - 重启设备
sudo reboot
6.2 安装PyTorch 和 Torchvision
上述ultralytics 安装程序将安装Torch 和 Torchvision。但是,通过 pip 安装的这两个软件包无法在基于 ARM64 架构的 Jetson 平台上兼容运行。因此,我们需要手动安装预编译的PyTorch pip wheel,并从源代码编译/安装 Torchvision。
- 卸载当前安装的PyTorch 和 Torchvision
pip uninstall torch torchvision - 根据 JP5.1.3 安装PyTorch 2.1.0
sudo apt-get install -y libopenblas-base libopenmpi-dev wget https://developer.download.nvidia.com/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl pip install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl - 根据PyTorch v2.1.0 安装 Torchvision v0.16.2
sudo apt install -y libjpeg-dev zlib1g-dev git clone https://github.com/pytorch/vision torchvision cd torchvision git checkout v0.16.2 python3 setup.py install --user
访问此页面可访问针对不同 JetPack 版本的所有不同版本的PyTorch 。有关PyTorch, Torchvision 兼容性的更详细列表,请点击此处。
七、在 NVIDIA Jetson 上使用TensorRT
在Ultralytics 支持的所有模型导出格式中,TensorRT 在使用英伟达 Jetson 设备时推理性能最佳,我们建议在使用 Jetson 时使用TensorRT 。我们还在此处提供了有关TensorRT 的详细文档。
八、将模型转换为TensorRT 并运行推理
PyTorch 格式的YOLOv8n 模型转换为TensorRT 格式,以便使用导出的模型进行推理。
示例
from ultralytics import YOLO # Load a YOLOv8n PyTorch model model = YOLO('yolov8n.pt') # Export the model model.export(format='engine') # creates 'yolov8n.engine' # Load the exported TensorRT model trt_model = YOLO('yolov8n.engine') # Run inference results = trt_model('https://ultralytics.com/images/bus.jpg')# Export a YOLOv8n PyTorch model to TensorRT format yolo export model=yolov8n.pt format=engine # creates 'yolov8n.engine' # Run inference with the exported model yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg'
九、论据
| 钥匙 | 价值 | 说明 |
|---|---|---|
format | 'engine' | 格式导出到 |
imgsz | 640 | 图像尺寸标量或(高,宽)列表,即(640,480) |
half | False | FP16 量化 |
十、英伟达 Jetson OrinYOLOv8 基准测试
YOLOv8 以下基准测试由Ultralytics 团队在 3 种不同的模型格式上运行,测量速度和精度:PyTorch 、TorchScript 和TensorRT 。基准测试在搭载 Jetson Orin NX 16GB 设备的 Seeed Studio reComputer J4012 上运行,精度为 FP32,默认输入图像大小为 640。
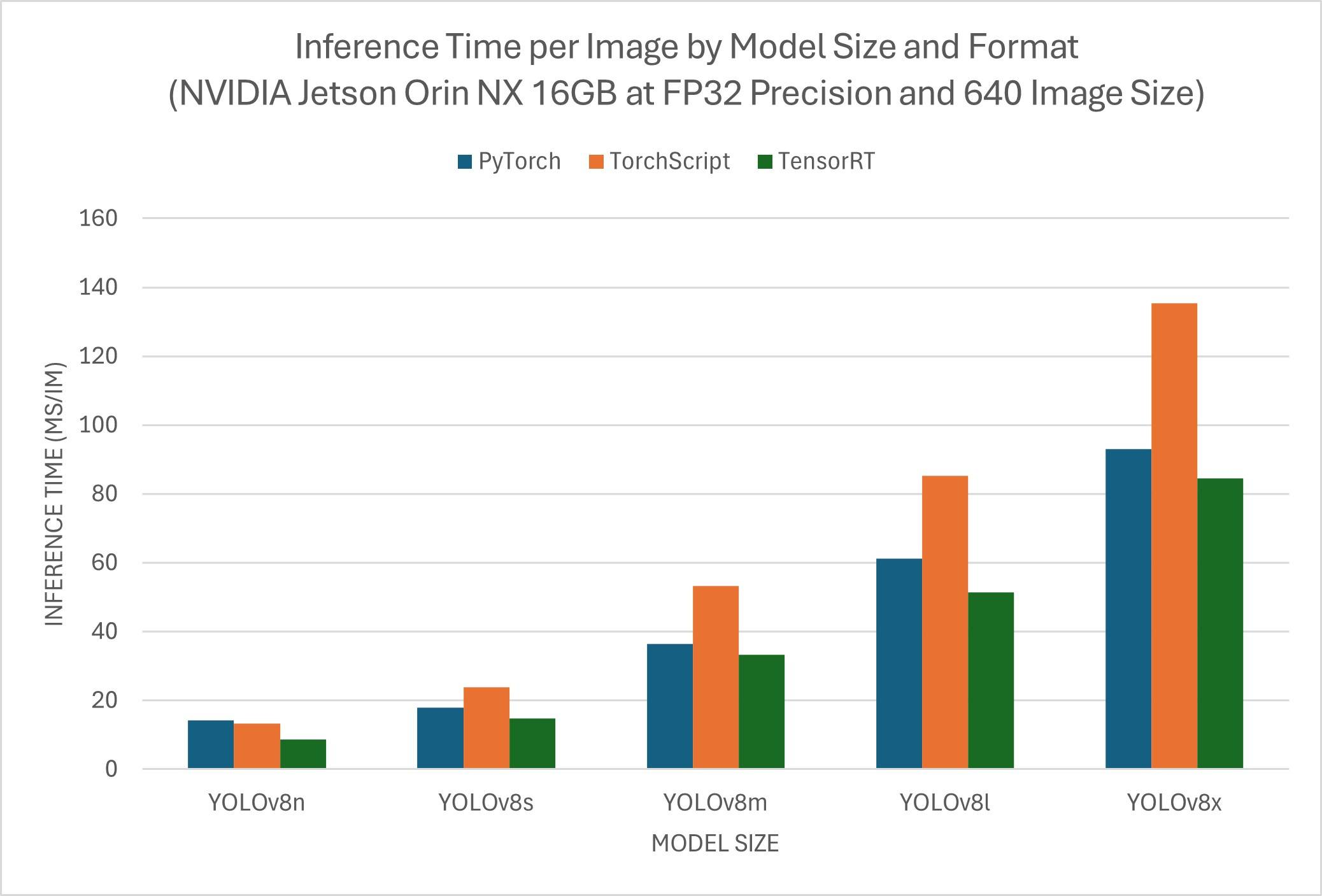
| 模型 | 格式 | 现状 | 大小(MB) | mAP50-95(B) | 推理时间(毫秒/分钟) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.4473 | 14.3 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.4520 | 13.3 |
| YOLOv8n | TensorRT | ✅ | 13.6 | 0.4520 | 8.7 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.5868 | 18 |
| YOLOv8s | TorchScript | ✅ | 43.0 | 0.5971 | 23.9 |
| YOLOv8s | TensorRT | ✅ | 44.0 | 0.5965 | 14.82 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.6101 | 36.4 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.6125 | 53.34 |
| YOLOv8m | TensorRT | ✅ | 100.3 | 0.6123 | 33.28 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.6588 | 61.3 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.6587 | 85.21 |
| YOLOv8l | TensorRT | ✅ | 168.3 | 0.6591 | 51.34 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.6650 | 93 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.6651 | 135.3 |
| YOLOv8x | TensorRT | ✅ | 261.8 | 0.6645 | 84.5 |
该表显示了三种不同格式(PyTorch,TorchScript,TensorRT )下的五个不同模型(YOLOv8n,YOLOv8s,YOLOv8m,YOLOv8l,YOLOv8x )的基准结果,并给出了每种组合的状态、大小、mAP50-95(B) 指标和推理时间。
请访问此链接,查看 Seeed Studio 在不同版本的英伟达™(NVIDIA®)Jetson 硬件上运行的更多基准测试结果。
十一、复制我们的结果
要在所有导出格式上重现上述Ultralytics 基准,请运行此代码:
示例
from ultralytics import YOLO # Load a YOLOv8n PyTorch model model = YOLO('yolov8n.pt') # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats results = model.benchmarks(data='coco8.yaml', imgsz=640)# Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats yolo benchmark model=yolov8n.pt data=coco8.yaml imgsz=640备注
目前只有PyTorch 、Torchscript 和TensorRT 可与基准测试工具配合使用。我们将在未来进行更新,以支持其他出口。
十二、使用英伟达™ Jetson 时的最佳实践
在使用英伟达™(NVIDIA®)Jetson 时,需要遵循一些最佳实践,以便在运行YOLOv8 的英伟达™(NVIDIA®)Jetson 上实现最高性能。
-
启用 MAX 功率模式
sudo nvpmodel -m 0在 Jetson 上启用 MAX Power 模式将确保所有 CPU 和 GPU 内核都处于开启状态。
-
启用 Jetson 时钟
sudo jetson_clocks启用 Jetson Clocks 可确保所有 CPU 和 GPU 内核都以最高频率运行。
-
安装 Jetson Stats 应用程序
我们可以使用 jetson stats 应用
sudo apt update sudo pip install jetson-stats sudo reboot jtop程序监控系统组件的温度,检查其他系统细节,如查看 CPU、GPU、RAM 利用率,更改电源模式,设置为最大时钟,检查 JetPack 信息等。
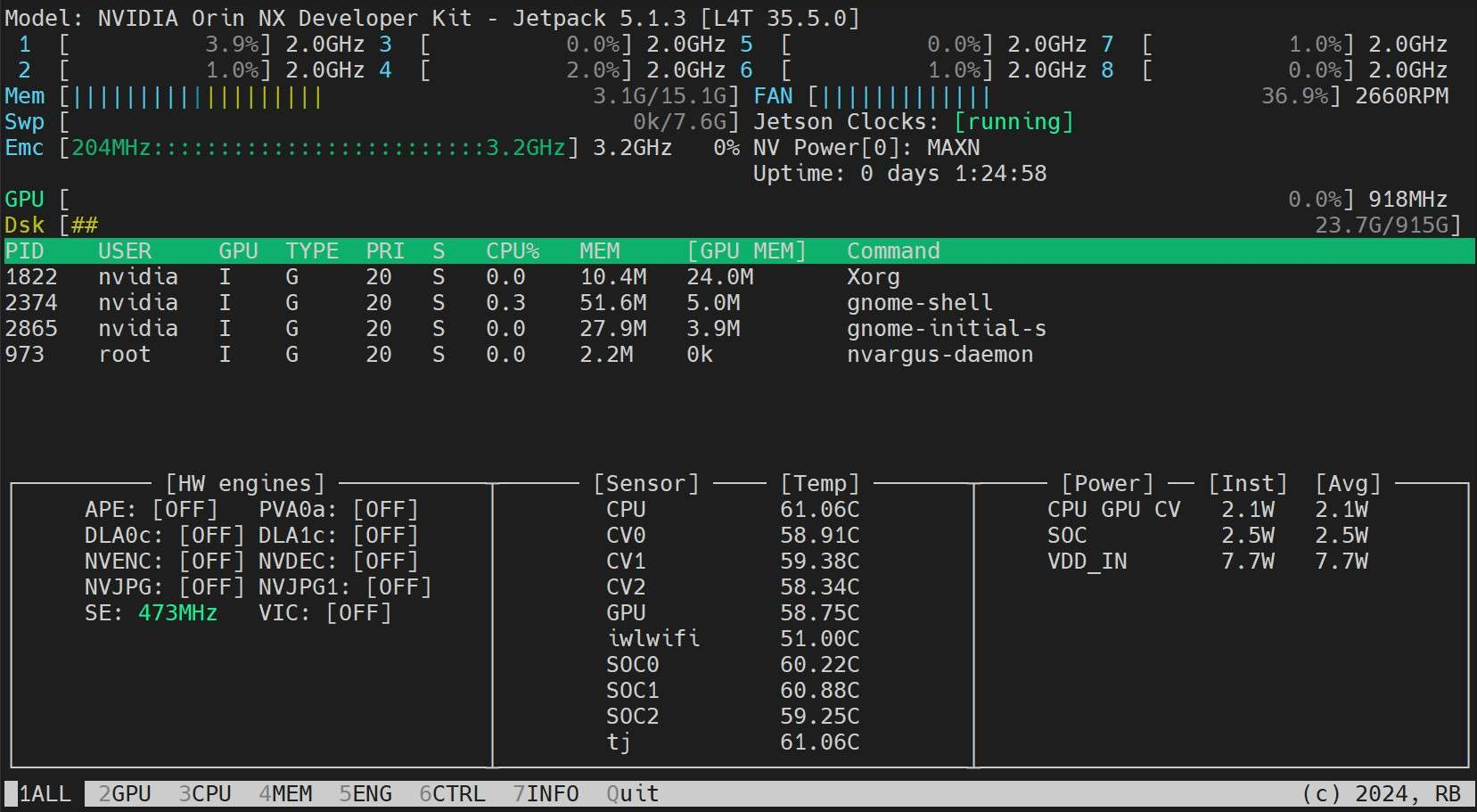
十三、下一步工作
恭喜您在 NVIDIA Jetson 上成功设置YOLOv8 !如需进一步学习和支持,请访问Ultralytics YOLOv8 Docs 获取更多指南!
![[Vue warn]: useModel() called with prop “xxx“ which is not declared](https://img-blog.csdnimg.cn/direct/3bf29b7e9600463cb439c27515b92744.png)







![[MySQL]运算符](https://img-blog.csdnimg.cn/direct/8e5a7f524f644fe1a9a4149551a65a83.png)